Мы много писали о возможностях новой версии платформы VMware vSphere 7 (например, тут и тут), но нововведений там столько, что это не уместить и в десять статей. Сегодня мы поговорим об изменениях в структуре разделов
(Partition Layout), которые произошли в VMware ESXi 7.
Первое, что надо отметить, что до vSphere 7 разделы были фиксированного объема, а их нумерация была статической, что ограничивало возможности по управлению ими, например, в плане поддержки больших модулей, функций отладки и стороннего ПО.
Поэтому в vSphere 7 были увеличены размеры загрузочных областей, а системные разделы, которые стали расширяемыми, были консолидированы в один большой раздел.
В VMware vSphere 6.x структура разделов выглядела следующим образом:
Как мы видим, размеры разделов были фиксированы, кроме раздела Scratch и опционального VMFS datastore. Они зависят от типа загрузочного диска (boot media) и его емкости.
В VMware vSphere 7 произошла консолидация системных разделов в область ESX-OSData:
Теперь в ESXi 7 есть следующие 4 раздела:
System boot - хранит boot loader и модули EFI. Формат: FAT16.
Boot-banks (2 штуки)
- системное пространство для хранения загрузочных модулей ESXi. Формат: FAT16.
ESX-OSData - унифицированное хранилище дополнительных модулей, которые не необходимы для загрузки. К ним относятся средства конфигурации и сохранения состояния, а также системные виртуальные машины. Формат: VMFS-L. Для этой области нужно использовать долговременные хранилища на базе надежных устройств.
Как вы видите, ESX-OSData разделен на две части: ROM-data и RAM-data. Часто записываемые данные, например, логи, трассировка томов VMFS и vSAN EPD, глобальные трассировки, горячие базы данных - хранятся в RAM-data. В области ROM-data хранятся нечасто используемые данные, например, ISO-образы VMware Tools, конфигурации, а также дампы core dumps.
В зависимости от размера устройства, куда устанавливается ESXi, меняется и размер всех областей, кроме system boot:
Если размер устройства больше 128 ГБ, то ESXi 7 автоматически создает VMFS-тома.
Когда вы используете для запуска ESXi устройства USB или карточки SD, то раздел ESX-OSData создается на долговременном хранилище, таком как HDD или SSD. Когда HDD/SSD недоступны, то ESX-OSData будет создан на USB-устройстве, но он будет содержать только ROM-data, при этом RAM-data будет храниться на RAM-диске (и не сохранять состояние при перезагрузках).
Для подсистем ESXi, которым требуется доступ к содержимому разделов, используются символьные ссылки, например, /bootbank и /altbootbank. А по адресу /var/core лежат дампы core dumps:
В VMware vSphere Client можно посмотреть информацию о разделах на вкладке Partition Details:
Ту же самую информацию можно получить и через интерфейс командной строки ESXi (команда vdf):
Обратите внимание, что соответствующие разделы смонтированы в BOOTBANK1 и 2, а также OSDATA-xxx.
Кстати, вы видите, что OSDATA имеет тип файловой системы Virtual Flash File System (VFFS). Когда OSDATA размещается на устройствах SDD или NVMe, тома VMFS-L помечаются как VFSS.
ESXi поддерживает множество устройств USB/SD, локальных дисков HDD/SSD, устройств NVMe, а также загрузку с тома SAN LUN. Чтобы установить ESXi 7 вам нужно выполнить следующие требования:
Boot media размером минимум 8 ГБ для устройств USB или SD
32 ГБ для других типов устройств, таких как жесткие диски, SSD или NVMe
Boot device не может быть расшарен между хостами ESXi
Если вы используете для установки ESXi такие хранилища, как M.2 или другие не-USB девайсы, учитывайте, что такие устройства могут быстро износиться и выйти из строя, например, если вы используете хранилища VMFS на этих устройствах. Поэтому удалите тома VMFS с таких устройств, если они были созданы установщиком по умолчанию.
Как вы знаете, компания VMware выпустила платформу VMware vSphere 7 в начале апреля этого года после громкого анонса месяцем ранее. В конце апреля VMware опубликовала интересную новость с результатами исследования среди пользователей, которые тестировали бета-версию vSphere 7 и потом прошли опрос, где одним из вопросов был "Почему бы вы хотели обновиться?". Собственно, вот его результаты...
Компания VMware выпустила на днях обновление одного из самых главных своих документов - "Performance Best Practices for VMware vSphere 7.0". Мы не зря в заголовке назвали это книгой, так как данный документ представляет собой всеобъемлющее руководство, где рассматриваются все аспекты поддержания и повышения производительности новой версии платформы VMware vSphere 7.0 и виртуальных машин в контексте ее основных возможностей.
На 96 листах очень подробно описаны лучшие практики для администраторов платформы и гостевых ОС:
Вот все корневые разделы этого руководства:
Persistent memory (PMem), including using PMem with NUMA and vNUMA
Getting the best performance from NVMe and NVME-oF storage
AMD EPYC processor NUMA settings
Distributed Resource Scheduler (DRS) 2.0
Automatic space reclamation (UNMAP)
Host-Wide performance tuning (aka, “dense mode”)
Power management settings
Hardware-assisted virtualization
Storage hardware considerations
Network hardware considerations
Memory page sharing
Getting the best performance from iSCSI and NFS storage
Для администраторов больших инфраструктур, активно внедряющих новые технологии (например, хранилища с Persistent Memory или DRS 2.0), появилось много всего нового и интересного, поэтому с книжкой нужно хотя бы ознакомиться по диагонали, останавливаясь на новых функциях ESXi 7 и vCenter 7.
Скачать PDF-версию "Performance Best Practices for VMware vSphere 7.0" можно по этой ссылке.
За время карантина компания StarWind Software выпустила пару небольших обновлений своего флагманского продукта StarWind Virtual SAN V8, предназначенного для создания программных и программно-аппаратных хранилищ под виртуализацию.
Продукт продолжает развиваться, ведется большая работа над улучшением производительности и ошибками, давайте посмотрим, что в нем появилось интересного для платформ vSphere и Hyper-V:
Для виртуального модуля StarWind VSAN for vSphere OVF (версия 20200515) была обновлена версия ядра Linux.
Функция полной синхронизации с проверкой контрольных сумм (CRC), добавленная в прошлом релизе, теперь используется только для хранилищ на базе MS Storage Spaces. В этом случае тип синхронизации (Full или Full hash) показан в Management Console.
Для старых хранилищ используется старый алгоритм с копированием данных без дополнительной проверки CRC, чтобы не влиять на производительность.
Для запроса CRC исправлена проблема с Memory alignment. Также была исправлена проблема совместимости для виртуального модуля StarWind VSA.
Множество исправлений ошибок, в том чиле важных с возможным повреждением данных - поэтому обязательно нужно обновиться.
StarWindX PowerShell Module
Добавлена проверка размера сектора для образа Flat Image - нельзя создать Flat Device с размером сектора 512 бай при физическом размере 4096 байт.
Добавлен параметр валидации формата (format) для вызова Add-RamDevice. Допустимые значения: fat16, fat32, ntfs, raw.
Добавлен параметр "force" для команды "remove".
Добавлено свойство CreateTapeOnExport для вызова VTL ApplyReplicationSettings(). Подробнее в сэмпле скрипта VTLReplicationSettings.ps1.
Нотификации по электронной почте и в интерфейсе
Запись нотификаций в текстовый файл не всегда теперь держит его открытым, а открывает и закрывает при необходимости.
Улучшена безопасность при работе с SMTP и пофикшен баг с отсылкой письма без аутентификации.
Установщик
Число файлов в Log Rotate было увеличено до 20 во время обновлений существующих установок.
Management Console
Пофикшена ошибка с отображением событий из Event Log в зоне нотификаций. Иногда эти события не отображались.
Хранилища Flat Storage
Улучшена обработка ответов для команд UNMAP/TRIM от хранилищ с файловой системой ReFS.
Прочее
Исправления для процессинга команды EXTENDED COPY(LID4), которая возвращала ошибки в прошлых версиях.
Скачать самый свежий релиз StarWind Virtual SAN V8 for Hyper-V от 6 мая 2020 (build 13586) года можно по этой ссылке, а StarWind VSAN for vSphere OVF (версия 20200515 от 18 мая) - по этой ссылке.
Frank Denneman обратил внимание на одну интересную новую функцию VMware vSphere 7 - возможность миграции vMotion для виртуальных машин с привязанными ISO-образами.
Как знают администраторы vSphere, часто приходится привязывать ISO-образ к консоли виртуальной машины, чтобы установить какое-то ПО. Нередко этот ISO находится на локальном хранилище машины администратора:
В таком случае, при попытке миграции vMotion данной виртуальной машины выдается ошибка о невозможности выполнения операции в связи с привязанным и активным локальным ISO к виртуальному устройству CD/DVD:
Усугубляется это еще и тем, что такие машины исключаются из миграций DRS, а также не могут быть смигрированы автоматически при переводе хоста ESXi в режим обслуживания (Maintenance mode). Как это обычно бывает, администратор узнает об этом в самом конце, минут через 10 после начала операции по переводу на обслуживание - и агрится от такой ситуации.
Поэтому в VMware vSphere 7 такое поведение пофиксили: теперь при миграции vMotion
виртуальное устройство с локальным файлом отсоединяется от исходной машины по команде процесса VMX, все операции с ним буферизуются, далее происходит миграция машины на другой хост, подцепление к нему виртуального устройства с вашим ISO и накатывание буфера.
После переключения машины на другой хост ESXi, VMRC-консоль показывает подключение вашего локального ISO уже к целевой машине:
Казалось бы, мелочь, но иногда может сэкономить немного времени администратора. Для работы этой фичи нужно, чтобы оба хоста VMware ESXi были седьмой версии или выше.
Не так давно компания VMware объявила о выходе новой версии решения Cloud Director 10.1, предназначенного для создания интегрированной платформы для сервис-провайдеров, предоставляющих виртуальные машины в аренду. О прошлой версии vCloud Director 10.0 мы писали осенью прошлого года вот тут. Обратите внимание, что из слова vCloud исчезла буква "v", и теперь продукт называется Cloud Director.
Давайте посмотрим, что нового появилось в Cloud Director 10.1:
App Launchpad - это средство, построенное на базе решения купленной компании Bitnami. Оно позволяет сервис-провайдерам развертывать для пользователей различные приложения, в том числе кастомные, чтобы дать им единое решение для полного цикла предоставления сервиса IaaS<>SaaS. Более подробно об этом продукте написано здесь.
Container Service Extension (CSE) 2.6 - теперь у пользователей облаков появится еще больше полезных средств для развертывания приложений в контейнерах Kubernetes. Эта версия дает не только консольные инструменты, но и визуализует некоторые вещи по инфраструктуре контейнеров в интерфейсе.
Object Storage Extension (OSE) 1.5 - за счет этого расширения пользователи получают S3-совместимый API, с помощью которого можно использовать хранилища Cloudian S3, в том числе на платформе Dell ECS EX.
Terraform VMware Cloud Director Provider 2.8 - с помощью этого плагина облачные провайдеры могут развертывать инфраструктуру из заранее заскриптованных сценариев для виртуальных датацентров (Infrastructure-as-code). Здесь появилась поддержка новой версии Cloud Director.
Tenant App 2.4 - средствами этого виртуального модуля можно потребление ресурсов клиентами облака и стоимость их обслуживания (прайсинг и биллинг). В новой версии этого средства теперь есть более детальная поддержка сетевого стека NSX, чтобы учитывать потребление ресурсов сети клиентами и, например, чарджить их на базе предоставляемой полосы.
NSX-T Migration Tool - это средство для переезда с платформы NSX-V. Для виртуальных машин во время миграции используется vMotion, поэтому процесс переезда возможен без простоя сервисов. Более подробно об этом написано тут.
Улучшения NSX-T - здесь появилось очень много улучшений. Теперь процесс развертывания не требует работы в нескольких экранах, появились улучшения IPSec, а также многое было сделано в плане безопасности и улучшения работы в различных топологиях сети.
Encryption as a service - теперь сервис-провайдеры могут использовать шифрование vSphere Encryption. Для этого вам потребуется развернуть инфраструктуру key management server (KMS) на базе партнерских решений, таких как Fortanix или Dell CloudLink.
Более подробно о VMware Cloud Director 10.1 можно почитать в Release Notes. Основная страница для сервис-провайдеров находится тут.
Недавно компания VMware выпустила интересный документ, объясняющий иногда возникающие проблемы с производительностью операций чтения с NFS-хранилищ для серверов VMware ESXi версий 6.x и 7.x. В документе "ESXi NFS Read Performance: TCP Interaction between Slow Start and Delayed Acknowledgement" рассматривается ситуация с эффектом Slow Start и Delayed Acknowledgement.
Этот эффект возникает в некоторых сценариях с низким процентом потери пакетов (packet loss), когда используется fast retransmit на передатчике и selective acknowledgement (SACK) на приемнике. Для некоторых реализаций стека TCP/IP в случаях, когда передатчик входит в состояние slow start при включенной отложенной квитанции приема пакетов (delayed ACK), квитанция о приеме первого сегмента slow start может быть отложена на время до 100 миллисекунд. Этого оказывается достаточно, чтобы снизить последовательную скорость чтения с NFS-хранилища на величину до 35% (при этом потери пакетов не будут превышать 0.02%).
Более подробно механика возникновения этого эффекта описана в документе. Там же рассказывается и метод борьбы с этим: если вы подозреваете, что у вас подобная проблема, надо просто отключить ESXi NFS Client Delayed ACK и посмотреть, стало ли лучше. Для этого в консоли нужно выполнить следующую команду:
esxcli system settings advanced set -o "/SunRPC/SetNoDelayedAck" -i 1
После этого убеждаемся, что настройка установлена:
esxcli system settings advanced list | grep -A10 /SunRPC/SetNoDelayedAck
Более подробно об этом можно также почитать в KB 59548.
После этого нужно снова провести тесты на последовательное чтение. Если не помогло, то лучше вернуть настройку назад, указав в качестве параметра первой команды -i 0.
Как вы знаете, обновлением виртуальной инфраструктуры в VMware vSphere 7 вместо Update Manager теперь занимается комплексное средство vSphere Lifecycle Manager (vLCM). vLCM можно использовать для применения установочных образов, отслеживания соответствия (compliance) и приведения кластера к нужному уровню обновлений.
Одной из возможностей этого средства является функция проверок на совместимость (Compatibility Checks). Они нужны, например, в случаях, когда вы настроили интеграцию Hardware Support Manager (HSM) для серверов Dell или HP и хотите проверить оборудование развертываемого сервера на совместимость с ESXi. Это так называемые Hardware Compatibility Checks.
Во время проверок можно использовать кастомный образ ESXi с дополнениями Firmware и Drivers Addon для проверки образов от поддерживаемых вендоров на совместимость с имеющимся у вас оборудованием и установленной версией микрокода. Вот так в vLCM выглядит проверка соответствия для образов ESXi:
На этом скриншоте видно, что текущий уровень компонентов хоста ESXi не соответствует желаемым параметрам в плане версий Firmware аппаратных компонентов. В этом случае есть опция Remediate (кнопка вверху слева), которая позволяет привести хосты ESXi в соответствие, обновив микрокод аппаратных компонентов средствами Hardware Support Manager - и все это прямо из клиента vSphere Client, без сторонних консолей.
vLCM предоставляет также функции автоматической проверки (HCL Automatic Checks), с помощью которых можно автоматически и систематически искать несоответствия уровня firmware на хостах ESXi и сверять их с актуальной онлайн-базой VMware Compatibility Guide (VCG, он же Hardware Compatibility Guide - HCL).
Если вы зайдете в раздел Cluster > Updates, то увидите результат работы автоматического тестирования на совместимость с необходимыми деталями. Пока это доступно только для контроллеров хранилищ vSAN (storage controllers), что является критически важной точкой виртуальной инфраструктуры с точки зрения обновлений (стабильность, производительность).
На скриншоте ниже показаны результаты проверки совместимости в кластере для адаптера Dell HBA330. В данном случае видно, что на всех хостах установлена одинаковая и последняя версия firmware, что и является правильной конфигурацией:
По ссылке "View in HCL" вы сможете увидеть, что данный адаптер с данной версией микрокода действительно поддерживается со стороны VMware vSphere и vSAN.
Если вы на своем Mac решили установить VMware ESXi 7 в виртуальной машине на флешке, то с настройками по умолчанию этого сделать не получится - USB-устройство не обнаружится установщиком и не будет видно в разделе настроек USB & Bluetooth виртуальной машины.
Eric Sloof написал, что перед развертыванием ESXi, чтобы установщик увидел USB-диск, нужно перевести USB Compatibility в режим совместимости с USB 3.0:
После этого можно будет выбрать ваш USB-диск для установки ESXi 7.0:
Многие из вас знакомы с решением VMware App Volumes, которое предназначено для распространения готовых к использованию приложений VMware ThinApp посредством подключаемых виртуальных дисков к машинам. Те из вас, кто его используют, время от времени, наверняка, сталкиваются с проблемой недостатка места на пользовательских томах Writable Volumes, которые забиваются неизвестно чем:
Напомним, что Writable Volumes - это персонализированные тома, которые принадлежат пользователям. Они хранят настройки приложений, лицензионную информацию, файлы конфигураций приложений и сами приложения, которые пользователь установил самостоятельно. Один такой диск может быть назначен только одному десктопу, но его можно перемещать между десктопами. Соответственно, такие тома могут легко заполняться, и пользователи начинают жаловаться.
Aresh Sarkari написал полезный скрипт, который выявляет заполненные тома Writable Volumes в инфраструктуре App Volumes (меньше 3 ГБ свободного места), формирует CSV-файл с данными о них и посылает его по электронной почте администратору:
####################################################################
# Get List of Writable Volumes from AppVolumes Manager for free space less than 3 GB out of 30 GB
# Author - Aresh Sarkari (@askaresh)
# Version - V2.0
####################################################################
# Run at the start of each script to import the credentials
$Credentials = IMPORT-CLIXML "C:\Scripts\Secure-Creds\SCred_avmgr.xml"
$RESTAPIUser = $Credentials.UserName
$RESTAPIPassword = $Credentials.GetNetworkCredential().Password
$body = @{
username = “$RESTAPIUser"
password = “$RESTAPIPassword”
}
Invoke-RestMethod -SessionVariable DaLogin -Method Post -Uri "https://avolmanager.askaresh.com/cv_api/sessions” -Body $body
$output = Invoke-RestMethod -WebSession $DaLogin -Method Get -Uri "https://avolmanager.askaresh.com/cv_api/writables" -ContentType "application/json"
$output.datastores.writable_volumes | Select-Object owner_name, owner_upn,total_mb, free_mb, percent_available, status | Where-Object {$_.free_mb -lt 3072} | Export-Csv -NoTypeInformation -Append D:\Aresh\Writableslt3gb.$(Get-Date -Format "yyyyMMddHHmm").csv
#send an email (provided the smtp server is reachable from where ever you are running this script)
$emailfrom = 'writablevolumes@askaresh.com'
$emailto = 'email1@askaresh.com', 'email2@askaresh.com' #Enter your SMTP Details
$emailsub = 'Wrtiable Volumes Size (free_mb) less than 3 GB out of 30 GB - 24 Hours'
$emailbody = 'Attached CSV File from App Volumes Manager. The attachment included the API response for all the Writable Volumes less than 3 GB of free space'
$emailattach = "D:\Aresh\Writableslt3gb.$(Get-Date -Format "yyyyMMddHHmm").csv"
$emailsmtp = 'smtp.askaresh.com'
Send-MailMessage -From $emailfrom -To $emailto -Subject $emailsub -Body $emailbody -Attachments $emailattach -Priority High -DeliveryNotificationOption OnFailure -SmtpServer $emailsmtp
Последняя версия сценария PowerCLI для поиска заполненных томов доступна в репозитории на GitHub. Там же, кстати, есть сценарий для поиска Writable Volumes со статусом Disabled или Orphaned.
Не так давно мы писали о новых возможностях платформы для создания отказоустойчивых хранилищ виртуальных машин в инфраструктуре виртуализации VMware vSAN 7.0. Компания VMware недавно сделала доступными для загрузки все компоненты обновленной виртуальной инфраструктуры, но новые возможности получили далеко не все пользователи - их набор зависит от имеющейся лицензии.
Давайте посмотрим, какие возможности есть в каждом из четырех доступных изданий VMware vSAN 7.0:
Standard (гибридные хранилища HDD+SSD)
Advanced (All-Flash хранилища)
Enterprise (возможности для предприятий)
Enterprise Plus (гиперконвергентная инфраструктура)
Возможности vSAN 7
Политики хранилищ Storage Policy Based Management (SPBM)
На днях на сайте проекта VMware Labs появилась полезная администраторам vSphere штука - утилита vSphere Replication Capacity Planning, позволяющая определить реальное потребление трафика репликации виртуальными машинами и размер передаваемой дельты данных. Это позволяет планировать сетевую инфраструктуру и принимать решения о выделении канала еще до того, как вы включите репликацию для всех своих виртуальных машин.
Утилита Replication Capacity Planning показывает графики, касающиеся объема передачи сетевого трафика LWD (lightweight delta - изменения с момента последней репликации) во времени, а также метрики по размеру дельты в различных временных масштабах - часы, дни, недели и месяцы.
Также в результате работы этого средства для виртуальной машины будет показано, какой объем вычислительных ресурсов и хранилища под реплики вам потребуется на целевой площадке (без учета актуальной политики хранилищ там):
Решение vSphere Replication Capacity Planning развертывается как виртуальный модуль (Virtual Appliance), для его работы потребуется VMware ESXi 6.0 или более поздней версии. Скачать его можно по этой ссылке. Документация доступна здесь.
Недавно мы рассказывали о новых возможностях платформы VMware vSphere 7 и прочих обновлениях продуктовой линейки VMware, анонсированных одновременно с флагманским продуктом. Напомним эти статьи:
Сегодня мы расскажем еще об одном важном апдейте - новой версии набора решений для гибридной инфраструктуры VMware Cloud Foundation 4. О прошлой версии этого пакета VCF 3.9.1 мы писали вот тут. Как вы помните, он представляет собой комплексное программное решение, которое включает в себя компоненты VMware vRealize Suite, VMware vSphere Integrated Containers, VMware Integrated OpenStack, VMware Horizon, NSX и другие, работающие в онпремизной, облачной или гибридной инфраструктуре предприятия под управлением SDDC Manager.
Четвертая версия VCF включает в себя все самые последние компоненты, статьи с описанием которых мы привели выше:
Как мы видим, в стеке VCF появился принципиально новый компонент - VMware Tanzu Kubernetes Grid. Об инфраструктуре поддержки контейнеров в новой версии платформы vSphere мы уже писали тут и тут. В новой архитектуре VCF администраторы могут развертывать и обслуживать приложения в кластерах Kubernetes с помощью Kubernetes tools и restful API.
В то же время, технология vSphere with Kubernetes (она же Project Pacific) будет обеспечивать следующую функциональность:
Службы vSphere Pod Service на базе Kubernetes позволят исполнять узлы напрямую в гипервизоре ESXi. Когда администратор развертывает контейнеры через службы vSphere Pod Service, они получают тот же уровень безопасности, изоляции и гарантии производительности, что и виртуальные машины.
Службы Registry Service позволяют разработчикам хранить и обслуживать образы Docker и OCI на платформе Harbor.
Службы Network Service позволяют разработчикам управлять компонентами Virtual Routers, Load Balancers и Firewall Rules.
Службы Storage Service позволяют разработчикам управлять постоянными (persistent) дисками для использования с контейнерами, кластерами Kubernetes и виртуальными машинами.
Все это позволяет получить все преимущества гибридной инфраструктуры (ВМ+контейнеры), о которых интересно рассказано здесь.
В остальном, VCF 4 приобретает все самые новые возможности, которые дают уже перечисленные новые релизы продуктов vSphere, vSAN, NSX-T и прочие.
Отдельно надо отметить очень плотную интеграцию vSphere Lifecycle Manager (vLCM) с платформой vSphere 7. vLCM дополняет возможности по управлению жизненным циклом компонентов инфраструктуры виртуализации, которые уже есть в SDDC Manager, но на более глубоком уровне - а именно на уровне управления firmware для узлов vSAN ReadyNodes (например, обновления микрокода адаптеров HBA).
Как и все прочие обновления линейки vSphere, апдейт VCF 4.0 ожидается уже в апреле. За обновлениями можно следить на этой странице.
Кластер отказоустойчивых хранилищ VMware vSAN состоит из нескольких хостов ESXi, на локальных хранилищах которых создаются дисковые группы, где размещаются данные виртуальных машин. В процессе создания, перемещения и удаления дисковых объектов ВМ распределение емкости на дисках может изменяться, иногда довольно существенно.
Все это приводит к дисбалансу кластера по дисковой емкости, что создает разную нагрузку на устройства, а это не очень хорошо:
В случае возникновения подобного дисбаланса в кластере VMware vSAN, в консоли vSphere Client на вкладке Monitor, в разделе vSAN Health появляется нотификация vSAN Disk Balance (выполняется эта проверка каждые 30 минут по умолчанию):
Чтобы устранить подобные ситуации, в кластере VMware vSAN есть механизм автоматической балансировки - Automatic Rebalance, который относится к дисковым объектам кластера vSAN, которые распределяются по дисковым группам разных хостов. Если данная настройка включена, то кластер vSAN автоматически наблюдает за балансом распределения дисковых объектов по хостам ESXi и выравнивает нагрузку на дисковые устройства.
По умолчанию пороговое значение составляет 30% (параметр Average Load Varinace - среднее значение разницы между минимальной и максимальной используемой емкостью на дисках в процентах). Это означает, что когда разница нагрузки между двумя дисковыми устройствами достигнет этого значения - начнется автоматическая перебалансировка и перемещение дисковых объектов. Она будет продолжаться, пока это значение не снизится до 15% или меньшей величины.
Также перебалансировка сама запустится, когда диск заполнен на более чем 80%. Надо помнить, что операция эта создает нагрузку на дисковые хранилища, поэтому надо учитывать, что у вас должен быть некоторый запас по производительности, чтобы автоматическая балансировка не съела полезные ресурсы.
В случае если у вас включена настройка Automatic Rebalance, кластер vSAN будет стараться поддерживать этот хэлсчек всегда зеленым. Если же отключена - то в случае возникновения дисбаланса загорится алерт, и администратору нужно будет вручную запустить задачу Rebalance Disks.
Эта опция называется ручной проактивной балансировкой кластера, она становится доступной когда разница в использовании дисковой емкости двух или более дисков начинает превышать 30%:
Если вы запускаете такую балансировку вручную, то продлится она по умолчанию 24 часа и затем сама остановится.
Надо понимать, что операция ребалансировки - это совершенно другая операция, нежели vSAN Resync. Она служит только целям сохранения равномерной нагрузки в кластере с точки зрения дисков.
Также есть возможность контроля операций ребалансировки с помощью интерфейса Ruby vSphere Console (RVC). Для этого вам нужно сменить пространство имен (namespace) на computers и выполнить следующую команду для кластера, чтобы посмотреть информацию о текущем балансе:
vsan.proactive_rebalance_info <номер кластера vSAN или символ "." для текущего пути консоли RVC>
Результат выполнения команды будет, например, таким:
/localhost/Test-DC/computers/Test-CL> vsan.proactive_rebalance_info .
2019-08-16 19:31:08 +0000: Retrieving proactive rebalance information from host esxi-3.labs.org ...
2019-08-16 19:31:08 +0000: Retrieving proactive rebalance information from host esxi-1.labs.org ...
2019-08-16 19:31:08 +0000: Retrieving proactive rebalance information from host esxi-2.labs.org ...
2019-08-16 19:31:09 +0000: Fetching vSAN disk info from esxi-3.labs.org (may take a moment) ...
2019-08-16 19:31:09 +0000: Fetching vSAN disk info from esxi-2.labs.org (may take a moment) ...
2019-08-16 19:31:09 +0000: Fetching vSAN disk info from esxi-1.labs.org (may take a moment) ...
2019-08-16 19:31:10 +0000: Done fetching vSAN disk infos
Proactive rebalance start: 2019-08-16 19:30:47 UTC
Proactive rebalance stop: 2019-08-17 19:30:54 UTC
Max usage difference triggering rebalancing: 30.00%
Average disk usage: 56.00%
Maximum disk usage: 63.00% (17.00% above minimum disk usage)
Imbalance index: 10.00%
No disk detected to be rebalanced
В этом случае ребалансировка не требуется. Если же вы, все-таки, хотите ее запустить, то делается это следующей командой:
vsan.proactive_rebalance -s <номер кластера vSAN или символ "." для текущего пути консоли RVC>
Ну и вы можете изменить время, в течение которого будет идти ручная ребалансировка. Для этого задайте значение в секундах следующей командой (в данном примере - это 7 дней):
Одновременно с анонсом новой версии платформы виртуализации VMware vSphere 7 компания VMware объявила и о скором выпуске решения vRealize Operations 8.1, предназначенного для управления и мониторинга виртуальной инфраструктуры. Напомним, что о прошлой версии vROPs 8.0 в рамках анонсов VMworld 2019 мы писали вот тут.
Давайте посмотрим, что нового появилось в vRealize Operations 8.1:
1. Операции с интегрированной инфраструктурой vSphere и Kubernetes.
vRealize Operations 8.1 позволяет обнаруживать и мониторить кластеры Kubernetes в рамках интегрированной с vSphere инфраструктуры с возможностью автодобавления объектов Supervisor Cluster, пространств имен (Namespaces), узлов (PODs) и кластеров Tanzu Kubernetes, как только вы добавите их в vCenter, используя функции Workload Management.
После этого вам станут доступны страницы Summary для мониторинга производительности, емкости, использования ресурсов и конфигурации Kubernetes на платформе vSphere 7.0. Например, функции Capacity forecasting покажут узкие места инфраструктуры на уровне узлов, а для ежедневных операций будут полезны дашборды, отчеты, представления и алерты.
2. Операции в инфраструктуре VMware Cloud on AWS.
Теперь в облаке VMware Cloud on AWS можно использовать токен VMware Cloud Service Portal для автообнаружения датацентров SDDC и настройки средств мониторинга в несколько простых шагов. Также можно будет использовать один аккаунт для управления несколькими объектами SDDC на платформе VMware Cloud on AWS, включая сервисы vCenter, vSAN и NSX, а также будет полная интеграция с биллингом VMConAWS.
В облаке можно использовать следующие дашборды:
Отслеживание использования ресурсов и производительность виртуальных машин, включая сервисы NSX Edge, Controller и vCenter Server.
Мониторинг ключевых ресурсов, включая CPU, память, диск и сеть для всей инфраструктуры и виртуальных машин.
Отслеживание трендов потребления ресурсов и прогнозирование таких метрик, как Time Remaining, Capacity Remaining и Virtual Machines Remaining.
Нахождение виртуальных машин, которые потребляют неоправданно много ресурсов и требуют реконфигурации на базе исторических данных.
Кроме этого, для сервисов VMware NSX-T будет осуществляться полная поддержка средств визуализации и мониторинга:
Ну и в релизе vROPs 8.1 есть полная интеграция функционала отслеживания затрат VMware Cloud on AWS с решением vRealize Operations в интерфейсе портала. Это позволит контролировать уже сделанные и отложенные затраты, а также детализировать их по подпискам, потреблению и датам оплат.
Также обновился механизм обследования AWS migration assessment, который теперь позволяет сохранять несколько результатов разных сценариев для дальнейшего анализа. Эти сценарии включают в себя различные варианты параметров Reserved CPU, Reserved Memory, Fault Tolerance, Raid Level и Discounts.
3. Функции мониторинга нескольких облаков (Unified Multicloud monitoring).
Теперь средства мониторинга предоставляют еще более расширенные функции, такие как поддержка Google Cloud Platform, улучшенная поддержка AWS и новый пакет Cloud Health Management pack.
Теперь в vROPS 8.1 есть следующие сервисы GCP:
Compute Engine Instance
Storage Bucket
Cloud VPN
Big Query
Kubernetes Engine
Пакет AWS Management Pack теперь поддерживает следующие объекты AWS Objects:
EFS
Elastic Beanstalk
Direct Connect Gateway
Target Group
Transit Gateway
Internet Gateway
Elastic Network Interface (ENI)
EKS Cluster
Пакет CloudHealth Management Pack был также улучшен, он включает в себя возможность передать данные о перспективах и ценообразовании GCP в vRealize Operations 8.1. Также вы сможете создавать любое число кастомных дэшбордов, комбинируя цены на различное соотношение ресурсов публичного, гибридного или частного облаков.
Как ожидается, vRealize Operations 8.1 выйдет в апреле этого года одновременно с релизом VMware vSphere 7. Мы обязательно напишем об этом.
Одновременно с этим было объявлено и о скором выпуске обновленной версии решения VMware Site Recovery Manager 8.3, предназначенного для обеспечения катастрофоустойчивости виртуальных датацентров. Напомним, что о прошлой версии SRM 8.2 мы писали в мае прошлого года. Главной новой возможностью тогда стала реализация функций продукта в виртуальном модуле (Virtual Appliance) на базе Photon OS.
Давайте посмотрим, что нового появилось в SRM 8.3:
1. Интеграция с Virtual Volumes (vVols).
Это было одной из самых ожидаемых возможностей SRM. Теперь тома vVols полностью поддерживаются для защиты с помощью SRM на базе технологий репликации на уровне дискового массива. Репликация для томов vVols работает на уровне отдельных виртуальных машин, а также в составе групп (replication groups).
Как некоторые знают, компонент VASA provider заменил модуль SRA (Storage Replication Adaptor), поэтому ежедневные операции теперь выполняются проще и быстрее. Сначала поддержка будет реализована для хранилищ Pure, HPE 3par и Nimble, но вскоре появится и для других вендоров. Список совместимости доступен здесь и будет постоянно обновляться.
2. Автоматическая защита виртуальных машин.
Раньше если вам было необходимо добавить ВМ в защищаемые на protected datastore, нужно было открыть консоль SRM и добавить ее в protection group. Теперь же, если машина перемещается на такой датастор с помощью vMotion или создается там администратором, то она автоматически попадает в состав защищенной группы.
Точно такая же автоматическая защита теперь распространяется и на тома vVols, которые поддерживаются, начиная с этой версии SRM.
Надо отметить, что если машина перемещается между датасторами через Storage vMotion, то она не попадает в protection group. Это сделано для того, чтобы предотвратить изменение protection group для машины во время этой операции.
3. Бесшовное изменение размера диска.
Раньше для изменения размера диска реплицируемой машины средствами vSphere Replication требовалось сделать несколько ручных операций на стороне таргета репликации. Теперь же эта операция делается автоматически, когда вы меняете размер диска исходной ВМ.
В SRM 8.1 появилась возможность сохранять и восстанавливать конфигурацию защищаемой среды, а в SRM 8.3 с помощью утилиты vSphere Replication Configuration Export/Import Tool можно делать то же самое для конфигураций репликации. Теперь администраторы могут сделать резервную копию конфигураций реплицируемых ВМ, включая RPO, MPIT, компрессии, подморозки (quiescing), шифрования, настройки датасторов и все прочее. Пока эта возможность доступна только через CLI.
5. Улучшения интерфейса.
В плане UI в SRM 8.3 было сделано очень много изменений, вот лишь некоторые из них:
Улучшения репортинга, включая возможность экспорта всех представлений в формат CSV.
Пользователь теперь может экспортировать детали репликации отдельных ВМ.
Интерфейс репликации теперь включает статистику lag time, которая показывает прошедшее с момента последней репликации время.
Возможность спрятать/показать колонки во всех табличных представлениях.
Список replications list теперь показывает ассоциированные protection groups.
Инженеры VMware приложили много усилий для внесения оптимизаций в эту версию vSphere Replication. Улучшения касаются как механизма первоначальной синхронизации, так и постоянной репликации машины под нагрузкой.
Расширенные возможности плагинов vRO для SRM и vSphere Replication, включая рабочие процессы для томов vVols.
Новые возможности для vROps Management packs, как для SRM, так и для vSphere Replication.
Улучшенная интеграция с хранилищами vSAN, которые теперь больше понимают о наличии данных реплик vSphere Replication.
Улучшения безопасности, включая поддержку FIPS в интерфейсе, и интеграция с шифрованием vSphere Trust Authority.
Доступность для загрузки VMware Site Recovery Manager 8.3 ожидается в апреле, одновременно с релизами vSphere 7 и vSAN 7. Пока за обновлениями можно следить на этой странице.
На днях компания VMware объявила о скором выпуске платформы виртуализации VMware vSphere 7.0, где будет много интересных новых возможностей. Одновременно с этим было объявлено и о будущем релизе новой версии VMware vSAN 7.0 - решения для организации отказоустойчивых хранилищ для виртуальных машин на базе локальных хранилищ хост-серверов VMware ESXi.
Давайте посмотрим, что интересного было анонсировано в новой версии решения VMware vSAN 7:
1. Интеграция с vSphere Lifecycle Manager (vLCM) для обновления кластеров
Ранее администраторы vSphere использовали Update Manager (VUM) для обновлений платформы и драйверов, а утилиты от производителей серверов для обновления их микрокода (firmware). Теперь эти процессы объединяются в единый механизм под управлением vSphere Lifecycle Manager:
vLCM можно использовать для применения установочных образов, отслеживания соответствия (compliance) и приведения кластера к нужному уровню обновлений. Это упрощает мониторинг инфраструктуры на предмет своевременных обновлений и соответствия компонентов руководству VMware Compatibility Guide (VCG) за счет централизованного подхода на уровне всего кластера.
2. Службы Native File Services for vSAN
С помощью служб Native File Services кластер vSAN теперь поддерживает управление внешними хранилищами NFS v3 и v4.1. Это позволяет использовать их совместно с другими возможностями, такими как службы iSCSI, шифрование, дедупликация и компрессия. Теперь через интерфейс vCenter можно управлять всем жизненным циклом хранилищ на базе разных технологий и превратить его в средство контроля над всей инфраструктурой хранения.
3. Развертывание приложений с использованием Enhanced Cloud Native Storage
Напомним, что функции Cloud Native Storage появились еще VMware vSAN 6.7 Update 3. Cloud Native Storage (CNS) - это функциональность VMware vSphere и платформы оркестрации Kubernetes (K8s), которая позволяет по запросу развертывать и обслуживать хранилища для виртуальных машин, содержащих внутри себя контейнеры. По-сути, это платформа для управления жизненным циклом хранения для контейнеризованных приложений.
Теперь эти функции получили еще большее развитие. Тома persistent volumes могут поддерживать шифрование и снапшоты. Также полностью поддерживается vSphere Add-on for Kubernetes (он же Project Pacific), который позволяет контейнеризованным приложениям быть развернутыми в кластерах хранилищ vSAN.
4. Прочие улучшения
Тут появилось довольно много нового:
Integrated DRS awareness of Stretched Cluster configurations. Теперь DRS отслеживает, что виртуальная машина находится на одном сайте во время процесса полной синхронизации между площадками. По окончании процесса DRS перемещает машину на нужный сайт в соответствии с правилами.
Immediate repair operation after a vSAN Witness Host is replaced.
Теперь процедура замены компонента Witness, обеспечивающего защиту от разделения распределенного кластера на уровне площадок, значительно упростилась. В интерфейсе vCenter есть кнопка "Replace Witness", с помощью которой можно запустить процедуру восстановления конфигурации и замены данного компонента.
Stretched Cluster I/O redirect based on an imbalance of capacity across sites. В растянутых кластерах vSAN можно настраивать защиту от сбоев на уровне отдельных ВМ за счет выделения избыточной емкости в кластере. В результате на разных площадках могут оказаться разные настройки, и появится дисбаланс по доступной емкости и нагрузке по вводу-выводу. vSAN 7 позволяет перенаправить поток ввода-вывода на менее загруженную площадку прозрачно для виртуальных машин.
Accurate VM level space reporting across vCenter UI for vSAN powered VMs. Теперь в vSAN 7 есть возможности точной отчетности о состоянии хранилищ для виртуальных машин, точно так же, как и для остальных хранилищ в представлениях Cluster View и Host View.
Improved Memory reporting for ongoing optimization. Теперь в интерфейсе и через API доступна новая метрика потребления памяти во времени. Она позволяет понять, как меняется потребление памяти при изменениях в кластере (добавление и удаление хостов, изменение конфигурации).
Visibility of vSphere Replication objects in vSAN capacity views. vSAN 7 позволяет администраторам идентифицировать объекты vSphere Replication на уровне виртуальных машин и кластеров, что упрощает управление ресурсами для нужд репликации.
Support for larger capacity devices. Теперь vSAN 7 поддерживает новые устройства хранения большой емкости и плотности носителей.
Native support for planned and unplanned maintenance with NVMe hotplug. Для устройств NVMe теперь доступна функция горячего добавления и удаления, что позволяет сократить время и упростить процедуру обслуживания.
Removal of Eager Zero Thick (EZT) requirement for shared disk in vSAN.
Теперь общие диски в vSAN не требуется создавать в формате EZT, что ускоряет развертывание в кластере vSAN нагрузок, таких как, например, Oracle RAC.
Больше информации о новых возможностях можно почитать в даташите о vSAN 7. Ну а технические документы будут постепенно появляться на StorageHub. Как и VMware vSphere 7, планируется, что решение vSAN 7 выйдет в апреле этого года.
На днях пришла пара важных новостей о продуктах компании StarWind Software, которая является одним из лидеров в сфере производства программных и программно-аппаратных хранилищ для виртуальной инфраструктуры.
StarWind HCA All-Flash
Первая важная новость - это выпуск программно-аппаратного комплекса StarWind HyperConverged Appliance (HCA) All-Flash, полностью построенного на SSD-накопителях. Обновленные аппаратные конфигурации StarWind HCA, выполненные в форм-факторе 1 или 2 юнита, позволяют добиться максимальной производительности хранилищ в рамках разумной ценовой политики. Да, All-Flash постепенно становится доступен, скоро это смогут себе позволить не только большие и богатые компании.
Решение StarWind HCA - это множество возможностей по созданию высокопроизводительной и отказоустойчивой инфраструктуры хранилищ "все-в-одном" под системы виртуализации VMware vSphere и Microsoft Hyper-V. Вот основные высокоуровневые возможности платформы:
Поддержка гибридного облака: кластеризация хранилищ и active-active репликация между вашим датацентром и любым публичным облаком, таким как AWS или Azure
Функции непрерывной (Fault Tolerance) и высокой доступности (High Availability)
Безопасное резервное копирование виртуальных машин
Проактивная поддержка вашей инфраструктуры специалистами StarWind
И многое, многое другое
Сейчас спецификация на программно-аппаратные модули StarWind HCA All-Flash выглядит так:
После развертывания гиперконвергентной платформы StarWind HCA она управляется с помощью единой консоли StarWind Command Center.
Ну и самое главное - программно-аппаратные комплексы StarWind HCA All-Flash полностью на SSD-дисках продаются сегодня, по-сути, по цене гибридных хранилищ (HDD+SSD). Если хотите узнать больше - обращайтесь в StarWind за деталями на специальной странице. Посмотрите также и даташит HCA.
Давайте посмотрим, что нового появилось в StarWind Virtual SAN V8 for Hyper-V:
Ядро продукта
Добавлен мастер для настройки StarWind Log Collector. Теперь можно использовать для этого соответствующее контекстное меню сервера в Management Console. Там можно подготовить архив с логами и скачать их на машину, где запущена Management Console.
Исправлена ошибка с заголовочным файлом, который брал настройки из конфига, но не существовал на диске, что приводило с падению сервиса.
Улучшен вывод событий в файлы журнала, когда в системе происходят изменения.
Улучшена обработка ответов на команды UNMAP/TRIM от аппаратного хранилища.
Добавлена реализация процессинга заголовка и блога данных дайждестов iSCSI на процессорах с набором команд SSE4.2.
Максимальное число лог-файлов в ротации увеличено с 5 до 20.
Механизм синхронной репликации
Процедура полной синхронизации была переработана, чтобы избежать перемещения данных, которые уже есть на хранилище назначения. Делается это путем поблочного сравнения CRC и копирования только отличающихся блоков.
Исправлена ошибка падения сервиса в случае выхода в офлайн партнерского узла при большой нагрузке на HA-устройство.
Значение по умолчанию пинга партнерского узла (iScsiPingCmdSendCmdTimeoutInSec) увеличено с 1 до 3 секунд.
Исправлена ошибка с утечкой памяти для состояния, когда один из узлов был настроен с RDMA и пытался использовать iSER для соединения с партнером, который не принимал соединений iSER.
Нотификации по электронной почте
Реализована поддержка SMTP-соединений через SSL/STARTTLS.
Добавлена возможность аутентификации на SMTP.
Добавлена возможность проверки настроек SMTP путем отправки тестового сообщения.
Компоненты VTL и Cloud Replication
Список регионов для всех репликаций помещен во внешний файл JSON, который можно просто обновлять в случае изменений на стороне провайдера.
Исправлена обработка баркодов с длиной, отличающейся от дефолтной (8 символов).
Исправлена ошибка падения сервиса при загрузке tape split из большого числа частей (тысячи).
Исправлены ошибки в настройках CloudReplicator Settings.
Модуль StarWindX PowerShell
Обновился скрипт AddVirtualTape.ps1, был добавлен учет параметров, чувствительных к регистру.
Для команды Remove-Device были добавлены опциональные параметры принудительного отсоединения, сохранения сервисных данных и удаления хранимых данных на устройстве.
Добавлен метод IDevice::EnableCache для включения и отключения кэша (смотрите примеры FlashCache.ps1 и FlushCacheAll.ps1).
VTLReplicationSettings.ps1 — для назначения репликации используется число, кодирующее его тип.
Свойство "Valid" добавлено к HA channel.
Сценарий MaintenanceMode.ps1 — улучшенная обработка булевых параметров при исполнении сценария из командной строки.
Тип устройства LSFS — удален параметр AutoDefrag (он теперь всегда true).
Средство управления Management Console
Небольшие улучшения и исправления ошибок.
Скачать полнофункциональную пробную версию StarWind Virtual SAN for Hyper-V можно по этой прямой ссылке. Release Notes доступны тут.
Таги: StarWind, Update, Storage, iSCSI, HCA, Hardware, SSD, HA, DR
Cody Hosterman, известный своими заметками про PowerCLI, написал интересную статью о том, как запоминать дефолтные параметры на примере свойств соединения с дисковым массивом. Это может вам оказаться полезным, например, в случае если вы работаете с дисковым массивом в интерактивном режиме, при этом не хотите каждый раз указывать параметры соединения.
К примеру, при использовании модуля PureStorage.FlashArray.VMware есть возможность передавать параметры соединения, сохраненные в глобальной переменной $Global:DefaultFlashArray. Неудобство этого метода в том, что каждый раз вы должны указывать параметр -Array:
Поэтому в PowerCLI заложен отличный механизм дефолтных параметров для нужных вам командлетов. Например, можно создать переменную с параметрами соединения с массивом:
Далее можно записать эту переменную в дефолтные параметры:
$PSDefaultParameterValues = @{
"*-pfa*:Array"=$flashArray;
}
Это позволит для параметра, называющегося Array применять параметры соединения из переменной $flashArray. При этом эти параметры будут применяться только для командлетов, содержащих "-pfa" в своем названии (они есть только в модуле PureStoragePowerShellSDK).
Для всего модуля и всех командлетов нет простого способа задать дефолтные параметры, но можно получить в сценарии список всех доступных командлетов и для всех них прописать правило использования параметра -Array:
После этого вы сможете просто использовать командлеты без параметров, например, Get-PfaVolumes, чтобы получить все тома с заданного в дефолтном соединении массива:
Аналогично способ будет работать и для всех остальных параметров командлетов и любых других модулей.
Свершилось. Компания Veeam Software, лидер в сфере средств для обеспечения доступности виртуальных датацентров, объявила о выпуске и доступности для загрузки новой версии пакета
Veeam Availability Suite v10, в состав которого входит решение для резервного копирования и репликации виртуальных машин Veeam Backup and Replication v10.
Таги: Veeam, Backup, Update, Replication, Availability Suire, DR
Интересные вещи делает наш коллега Jorge de la Cruz. Он скрупулезно и дотошно делает полезные дэшборды в Grafana для платформы виртуализации VMware vSphere и решения Veeam Availability Suite, которые могут помочь администраторам в решении повседневных задач мониторинга и траблшутинга.
Чтобы сделать доступными функции визуализации этих метрик, вам потребуется развернуть следующие компоненты:
Коллектор и нативный плагин Telegraf к VMware vSphere - агент, который собирает метрики в кластере и сохраняет их в базе данных InfluxDB.
InfluxDB - собственно, сама база данных, хранящая метрики.
Grafana - фреймворк, который используется для визуализации метрик из базы.
О том, как это все заставить работать, чтобы получать красивые дашборды, подробно написано вот тут и тут. Ниже мы лишь приведем примеры того, как это выглядит:
1. vSphere Overview Dashboard.
Здесь визуализуются все высокоуровневые параметры виртуальной инфраструктуры, такие как загрузка ресурсов кластера, заполненность хранилищ, состояние гипервизора и использование ресурсов виртуальными машинами.
Лайв-демо такого дэшборда доступно по этой ссылке.
2. vSphere Datastore Dashboard.
Тут можно найти все метрики, касающиеся хранилищ, включая параметры чтения и записи, и многое другое:
Лайв-демо такого дэшборда доступно по этой ссылке.
3. vSphere Hosts Dashboard.
Тут видны основные метрики с уровня хоста для каждого из серверов ESXi: конечно же, загрузка аппаратных ресурсов и сети, а также дисковые задержки (latency):
Лайв-демо такого дэшборда доступно по этой ссылке.
4. vSphere VMs Dashboard.
Здесь можно увидеть самые полезные метрики для всех виртуальных машин вашего датацентра. Здесь можно увидеть аптайм, загрузку системных ресурсов и сети, latency, счетчик CPU Ready и другое:
Лайв-демо такого дэшборда доступно по этой ссылке.
5. vSphere Hosts IPMI dashboard.
Этот дэшборд отображает информацию IPMI для серверов Supermicro и HPE, доступную через iLO. Пригодится, когда вам нужно взглянуть на статус ваших систем в распределенной инфраструктуре удаленных офисов и филиалов.
Кроме приведенных выше дэшбордов для VMware vSphere, у Jorge de la Cruz также есть несколько дэшбордов для решений Veeam Software:
Не так давно мы писали о политиках хранилищ SPBM на базе тэгов в кластере VMware vSAN. Это один из механизмов категоризации объектов, который может применяться не только к хранилищам, но и хостам, виртуальным машинам и другим объектам. Появился он еще в версии VMware vSphere 5.1.
На днях компания VMware выпустила интересный документ VMware vSphere 6.7 Tagging Best Practices, в котором описаны лучшие практики по использованию тэгов в виртуальной инфраструктуре.
В документе рассматривается использование API для тэгов, работа с которым происходит через интерфейсы Java или PowerShell.
Например, вот команда по выводу всех виртуальных машин, которым назначен определенный тэг:
// List tags associated with tagId from above
// Assumes tagAssociation object from above
List retDynamicIds = tagAssociation.listAttachedObjects(tagId);
А вот так можно вывести список всех тэгов для конкретной виртуальной машины:
$allCategoryMethodSVC = Get-CisService com.vmware.cis.tagging.category
$alltagMethodSVC = Get-CisService com.vmware.cis.tagging.tag
$allTagAssociationMethodSVC = Get-CisService com.vmware.cis.tagging.tag_association
# Use first VM from above list
$useThisVMID = $useTheseVMIDs[0]
$tagList = $allTagAssociationMethodSVC.list_attached_tags($useThisVMID)
У VMware обнаружилась полезная интерактивная инфографика, которая наглядно показывает, что происходит с дисковыми объектами виртуальных машин хоста кластера хранилищ VMware vSAN, когда его переводят в режим обслуживания (Maintenance Mode). Напомним, что о том, как это работает, мы подробно писали вот тут.
Чтобы посмотреть различные сценарии работы данного режима, нужно открыть страничку по этой ссылке и нажать на кнопку Explore maintenance mode:
Далее можно будет выбрать основные параметры перевода в этот режим.
Сначала указываем способ миграции данных:
Full data migration - данные копируются на другие хосты таким образом, чтобы обеспечить исполнения политики FTT/RAID на оставшемся наборе хостов ESXi при введении в режим обслуживания одного или двух хостов.
Ensure Accessibility – это миграция только тех компонентов, которые есть в кластере в единственном экземпляре. При этом, для некоторых объектов на период обслуживания не будет соблюдена политика Failures to tolerate (FTT).
No Data Migration – в этом случае никакие компоненты не будут перемещены с хоста, поэтому некоторые ВМ могут оказаться недоступными (если на этом хосте их дисковые компоненты находятся в единственном экземпляре, а уровень RAID недостаточен для предоставления доступа к объекту).
Потом надо задать значение политики FTT и тип организации избыточности RAID0 для FTT=0, RAID1 или RAID5 для FTT=1, RAID6 для FTT=2. А далее нужно указать, один или два хоста мы переводим в режим обслуживания.
Например, если мы укажем, что нам нужен тип миграции Full data migration, при этом надо соблюсти политику FTT=2/RAID-6, то система попросит добавить еще один хост ESXi в кластер, так как оставшихся 5 хостов в этом случае будет не хватать, чтобы обеспечить требуемые политики.
Ну а при выборе выполнимого сценария будет показана анимация происходящего при переводе одного или двух хостов в режим обслуживания процесса, который вовлекает перемещение дисковых объектов виртуальных машин на другие хосты.
Надо сказать, что не рекомендуется переводить сразу 2 хоста в режим обслуживания, так как это может привести к тому, что невозможно будет обеспечить требуемые политики FTT/RAID в имеющейся аппаратной конфигурации (хотя перевод двух хостов в maintenance mode вполне поддерживается со стороны vSAN).
В общем, интересная штука - попробуйте посмотреть, как визуализируются различные сценарии.
Сегодня мы расскажем об отличиях коммерческой и бесплатной версий одного из лучших решений для создания отказоустойчивых программных хранилищ под виртуальные машины StarWind Virtual SAN. Последний раз мы писали о сравнении возможностей платной и бесплатной версий в далеком 2017 году, и с тех пор, конечно же, много что изменилось.
Под конец года компания VMware выпустила очередной полезный администраторам VMware vSphere постер - VMware PowerCLI 11 Storage Module Reference Poster for vSAN. В постере приведено несколько полезных командлетов для последней версии PowerCLI, которые позволяют управлять хранилищами VMware vSAN с помощью модуля Storage.
С левой стороны перечислены все командлеты данного модуля, разбитые по группам, а справа приведены примеры использования различных команд и простых сценариев для выполнения типовых задач. Например, показано как узнать емкость датастора vSAN, установить VIB-пакет на хост vSAN или включить функцию vSAN Encryption в кластере.
Скачать постер VMware PowerCLI 11 Storage Module Reference Poster for vSAN можно по этой ссылке.
Многие администраторы виртуальных инфраструктур в курсе про технологию NVMe (интерфейс Non-volatile Memory дисков SSD), которая была разработана для получения низких задержек и эффективного использования высокого параллелизма твердотельных накопителей. Такие устройства хоть и стоят дороже, но уже показывают свою эффективность за счет использования десятков тысяч очередей команд, что дает очень низкие задержки, требующиеся в таких сферах, как системы аналитики реального времени, онлайн-трейдинг и т.п.
К сожалению, протокол iSCSI (да и Fibre Channel тоже) разрабатывался тогда, когда инженеры еще не думали об архитектуре NVMe и высоком параллелизме, что привело к тому, что если использовать iSCSI для NVMe, использование таких хранилищ происходит неэффективно.
Главная причина - это одна очередь команд на одно устройство NVMe, которую может обслуживать iSCSI-протокол, весь смысл параллелизма теряется:
Вторая проблема - это то, что iSCSI использует процессор для диспетчеризации операций ввода-вывода, создавая дополнительную нагрузку на серверы, а также имеет некоторые сложности по перенаправлению потоков операций для нескольких контроллеров NVMe и устройств хранения на них.
Для этого и был придуман протокол NVMe over Fabrics (NVMe-oF), который не имеет таких ограничений, как iSCSI. Еще один его плюс - это то, что он обратно совместим с такими технологиями, как InfiniBand, RoCE и iWARP.
Компания StarWind сделала свою реализацию данного протокола для продукта StarWind Virtual SAN, чтобы организовать максимально эффективное использование пространства хранения, организованного с помощью технологии NVMe. Об этом было объявлено еще осенью прошлого года. Он поддерживает 64 тысячи очередей, в каждой из которых, в свою очередь, может быть до 64 тысяч команд (в реальной жизни в одной очереди встречается до 512 команд).
Важный момент в реализации NVMe-oF - это применение технологии RDMA, которая позволяет не использовать CPU для удаленного доступа к памяти и пропускать к хранилищу основной поток управляющих команд и команд доступа к данным напрямую, минуя процессоры серверов и ядро операционной системы.
Также RDMA позволяет маппить несколько регионов памяти на одном NVMe-контроллере одновременно и организовать прямое общение типа точка-точка между инициаторами разных хостов (несколько Name Space IDs для одного региона) и этими регионами без нагрузки на CPU.
Такой подход, реализованный в продуктах StarWind, дает потрясающие результаты в плане производительности, о которых мы писали вот в этой статье. К этой статье можно еще добавить то, что реализация инициатора NVMe-oF на базе Windows-систем и таргета на базе Linux (который можно использовать в программно-аппаратных комплексах StarWind Hyperconverged Appliances, HCA) дала накладные издержки на реализацию всего 10 микросекунд по сравнению с цифрами, заявленными в даташитах производителя NVMe-устройств. Знающие люди поймут, насколько это мало.
Еще надо отметить, что бесплатный продукт StarWind NVMe-oF initiator - это единственная программная реализация инициатора NVMe-oF на сегодняшний день. В качестве таргета можно использовать решения Intel SPDK NVMe-oF Target и Linux NVMe-oF Target, что позволяет не зависеть жестко от решений StarWind.
Подробнее о StarWind NVMe-oF initiator можно узнать вот в этой статье. А загрузить его можно по этой ссылке.
На сайте проекта VMware Labs обновилась очередная полезная администраторам утилита - VMware OS Optimization Tool. Она позволяет подготовить гостевые ОС к развертыванию и проводить тюнинг реестра в целях оптимизации производительности, а также отключение ненужных сервисов и запланированных задач. Напомним, что о прошлой ее версии мы писали вот тут.
Давайте посмотрим, что нового появилось в OS Optimization Tool b1110 (а нового немало!):
1. Работа с шаблонами.
Изменены 2 существующих шаблона, чтобы покрыть соответствующие серверные ОС и реализовать поддержку Windows Server 2019 отдельно.
Windows 10 1507-1803 / Server 2016
Windows 10 1809-1909 / Server 2019
Старые шаблоны Windows Server 2016 были удалены.
2. Функции System Clean Up.
Добавлены параметры очистки системы в диалог Common Options, это убирает необходимость выполнять эти операции вручную. Следующие параметры были добавлены:
Deployment Image Servicing and Management (DISM)
Native Image Generator (NGEN)
Compact (Windows 10/ Server 2016/2019)
Disk Cleanup
3. Бэкграунд/обои рабочего стола.
Новая страница Common Options для настроек фонового изображения. Также можно дать возможность пользователю поменять обои.
4. Настройки визуальных эффектов.
Добавлена третья опция, которая выключает все визуальные эффекты, кроме smooth edges и use drop shadows. Это теперь опция по умолчанию.
5. Приложения Windows Store.
Новая страница в Common Options позволяет контролировать удаление приложений Windows Store. Приложения Windows Store App и the StorePurchaseApp по умолчанию остаются.
Также можно оставить следующие приложения:
Alarms & Clock
Camera
Calculator
Paint3D
Screen Sketch
Sound Recorder
Sticky Notes
Web Extensions
6. Значения по умолчанию.
Маленькая опция в таскбаре теперь не отмечена по умолчанию. В шаблонах Windows 10/ Server теперь следующие сервисы не выбраны по умолчанию:
Application Layering Gateway Service
Block Level Backup Engine Service
BranchCache
Function Discovery Provider Host
Function Discovery Resource Publication
Internet Connection Sharing
IP Helper
Microsoft iSCSI Initiator Service
Microsoft Software Shadow Copy Provider
Secure Socket Tunneling Protocol Service
SNMP Trap
SSDP Discovery
Store Storage Service
Volume Shadow Copy Service
Windows Biometric Service
7. Несколько новых оптимизаций.
Полностью отключить Smartscreen
Отключить Content Delivery Manager
Отключить User Activity History completely
Отключить Cloud Content
Отключить Shared Experiences
Отключить Server Manager для Windows Server OS
Отключить Internet Explorer Enhanced Security для Windows Server OS (не выбрано по умолчанию)
Отключить Storage Sense service
Отключить Distributed Link Tracking Client Service
Отключить Payments и NFC/SE Manager Service
Скачать VMware OS Optimization Tool можно по этой ссылке.
Как некоторые из вас знают, новый пакет продуктов для обеспечения доступности датацентра Veeam Availability Suite v10 был анонсирован еще в 2017 году. С тех пор лидер в сфере резервного копирования виртуальных машин, компания Veeam, выпускала обновления Veeam Availability Suite 9.5 (например, вот последний Update 4) и параллельно рассказывала о новых возможностях десятой версии.
Недавно мы анонсировали лайв-форум VeeamON Virtual 2019, который прошел 20 ноября. На форуме, собравшем 7 тысяч человек онлайн, компания Veeam сделала несколько интересных анонсов, где главным был рассказ о новых возможностях Veeam Availability Suite v10.
Вот эти возможности:
1. Масштабируемый репозиторий резервных копий.
Благодаря этой возможности будет доступна немедленная резервная копия в объектное хранилище. Ранее Veeam Cloud Tier перемещал резервные копии в объектное хранилище в соответствии с политикой хранения (через заданное число дней), теперь вы можете отправлять их туда сразу после их создания.
Copy Mode — это дополнительная политика, которую можно задать для объектных хранилищ в составе масштабируемого репозитория ("Copy all backups to object storage as they are created"). Любые выбранные файлы резервных копий, созданные в рамках обычных заданий резервного копирования или заданий автоматического переноса, будут скопированы в Capacity Tier. Это позволит в любой момент полностью соответствовать правилу резервного копирования "3-2-1", согласно которому один экземпляр данных должен храниться на удаленной площадке.
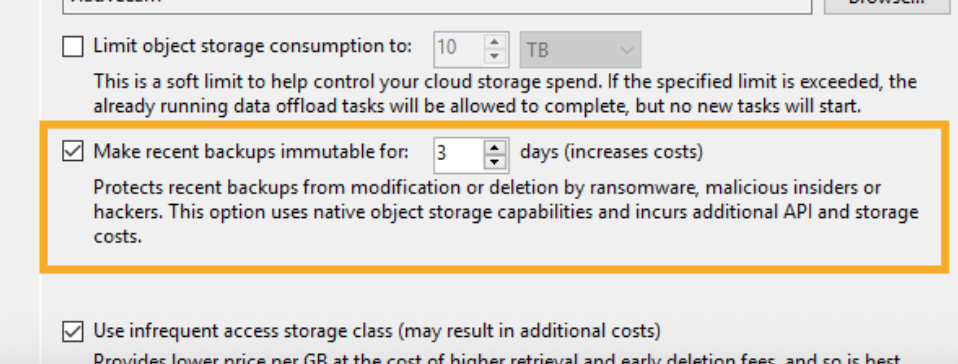
2. Блокировка объектов S3 (защита от удаления).
Функция Immutability в Veeam Backup and Replication 10 позволяет организовать блокировку файлов резервных копий, отправленных в объектное хранилище для предотвращения их удаления программами-вымогателями (Ransomware). Например, вы ставите такую блокировку (immutability flag) на 3 дня, чтобы защитить бэкапы не только от Ransomware, но и от потенциальных вредоносных действий собственных администраторов. В течение этого времени никто, включая администраторов, не сможет удалить эти резервные копии из облака S3.
Реализуется это с помощью стандартной функции "object lock", которая есть в сервисах Amazon AWS (к сожалению, ее пока нет на платформе Azure).
3. Резервное копирование NAS-хранилищ.
Теперь Veeam Backup and Replication сможет делать резервное копирование файлов SMB (CIFS) и NFS. Вы можете восстанавливать хранилище целиком, отдельные файлы или делать откат к предыдущим версиям файлов на заданный момент времени.
Функция появилась как ответ на запрос Enterprise-пользователей Veeam, которые хранят в 10 раз больше неструктурированных данных в файловых помойках, чем структурированных данных в виртуальных машинах.
Бэкап можно делать как с файловой шары напрямую, так и из нативного снапшота на хранилище (Native Storage Snapshot):
При восстановлении можно выбрать откат к точке во времени (Rollback to a point in time):
4. Прямое восстановление в VMware.
Работает это аналогично прямому восстановлению в Hyper-V. Поддерживает данная функция резервные копии как виртуальных, так и физических машин. С помощью Direct Restore to VMware можно, например, восстановить свой физический ноутбук в виртуальную машину на платформе vSphere.
5. Интерфейсы Data Integration API.
С помощью интерфейсов Veeam Data Integration API можно получать доступ к содержимому резервных копий в целях дата майнинга, который не нагружает производственные системы компании. Например, этот API можно использовать для аналитики по данным в резервных копиях ВМ или построения отчетов без нагрузки на продуктивные хранилища.
Выпуск Veeam Availability Suite v10, включая Veeam Backup and Replication v10, ожидается уже в самое ближайшее время. Следите за анонсами у нас на сайте!

 RSS
RSS